Les modèles d’IA générative ont rapidement prouvé leur capacité à exécuter des tâches techniques avec précision. L’ajout de capacités de raisonnement a ouvert la voie à des performances inattendues, permettant à ces systèmes de traiter des questions complexes et de fournir des réponses de qualité supérieure. Cependant, un rapport récent d’Apple remet en question certaines de ces avancées.
Les limites des modèles de raisonnement IA
La semaine dernière, Apple a publié un rapport de recherche intitulé « The Illusion of Thinking : Comprendre les forces et les limites des modèles de raisonnement à travers la lentille de la complexité des problèmes ». Ce document de 30 pages examine si les grands modèles de raisonnement (LRM), tels que les modèles d’OpenAI et d’Anthropic, réussissent réellement à fournir des capacités de « pensée » avancées.
Que sont les grands modèles de raisonnement (LRM) ?
Le terme « grands modèles de raisonnement » désigne des modèles avancés qui ont été popularisés par l’émergence de modèles tels que le modèle d’OpenAI. Le principe qui sous-tend ces LRM est que passer plus de temps à analyser une question peut améliorer la qualité de la réponse. Des techniques comme la « chaîne de pensée » (CoT) permettent à ces modèles de décomposer des problèmes complexes en étapes plus simples, facilitant ainsi la compréhension pour les utilisateurs.
Les LRM nécessitent plus de puissance de calcul
Cependant, ce traitement supplémentaire implique une demande accrue en ressources de calcul, rendant ces modèles plus coûteux et moins adaptés aux tâches quotidiennes. Les critères de référence utilisés pour tester ces LRM sont souvent basés sur des calculs mathématiques, ce qui pose des problèmes méthodologiques, comme le souligne Apple dans son rapport.
Les expériences d’Apple
Pour mieux évaluer ces modèles, Apple a mis en place quatre puzzles contrôlables :
- Tower of Hanoi : un défi de déplacement de disques.
- Checkers Jumping : un jeu de dames repositionnant des pièces.
- River Crossing : un exercice de traversée de rivière avec des formes.
- Blocks World : une tâche d’échange d’objets colorés.
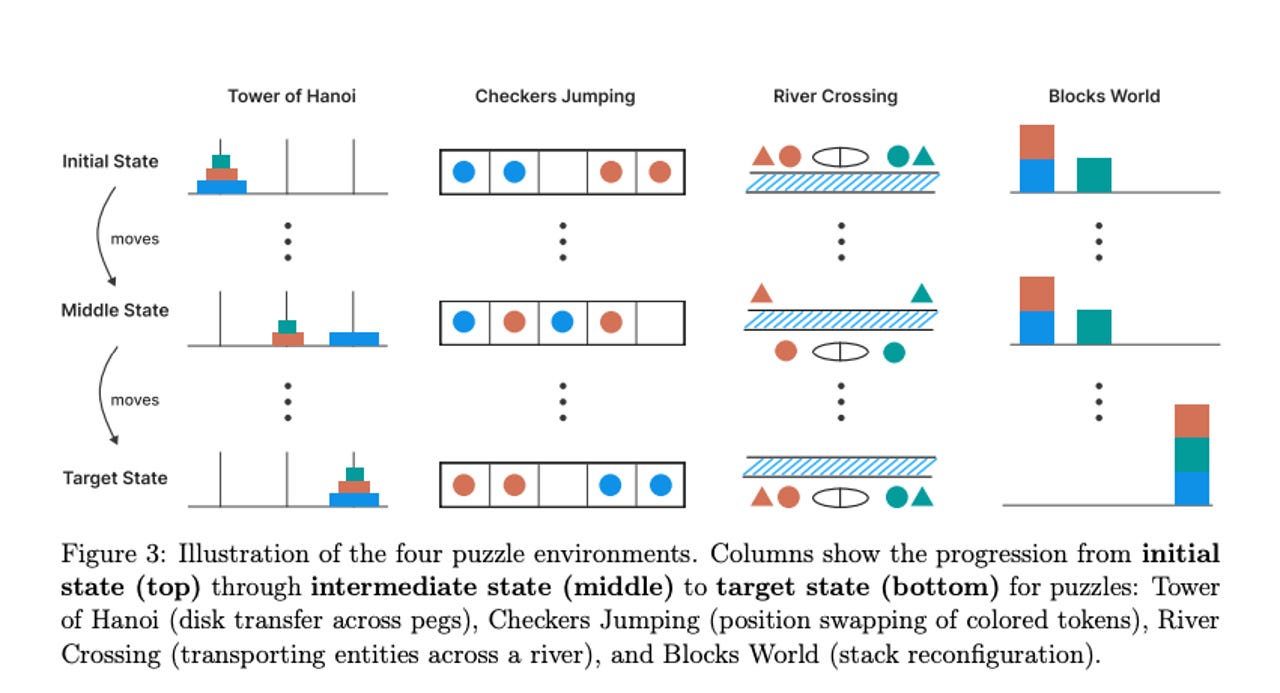
Ces puzzles ont été choisis pour créer un environnement contrôlé, permettant une analyse rigoureuse des schémas de raisonnement. En comparant les versions « pensantes » et « non pensantes » de modèles connus, Apple a pu manipuler la complexité des tâches.
Les résultats d’Apple
Les résultats révèlent que les modèles non réflexifs peuvent rivaliser, voire surpasser, les modèles réflexifs dans des situations de faible complexité. Cependant, l’écart de performance s’accroît dans des contextes de complexité moyenne. À des niveaux de complexité élevés, les performances des deux types de modèles chutent, indiquant des limites fondamentales.
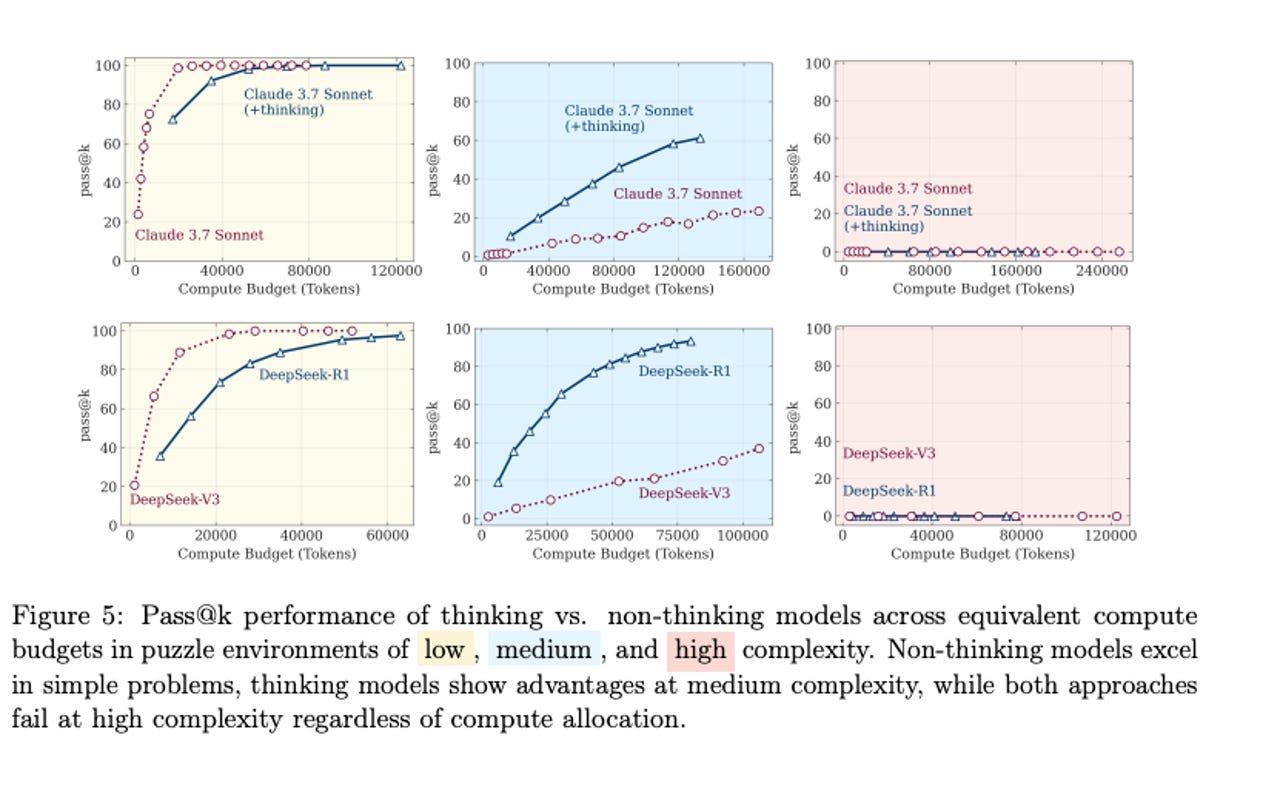
Un effondrement similaire avec cinq modèles de réflexion
Un effondrement de performance similaire a été observé avec cinq modèles de réflexion testés, confirmant que l’augmentation de la complexité entraîne une baisse de précision. Les modèles, même ceux conçus pour raisonner, ont montré des limites lorsqu’ils étaient confrontés à des défis plus difficiles.
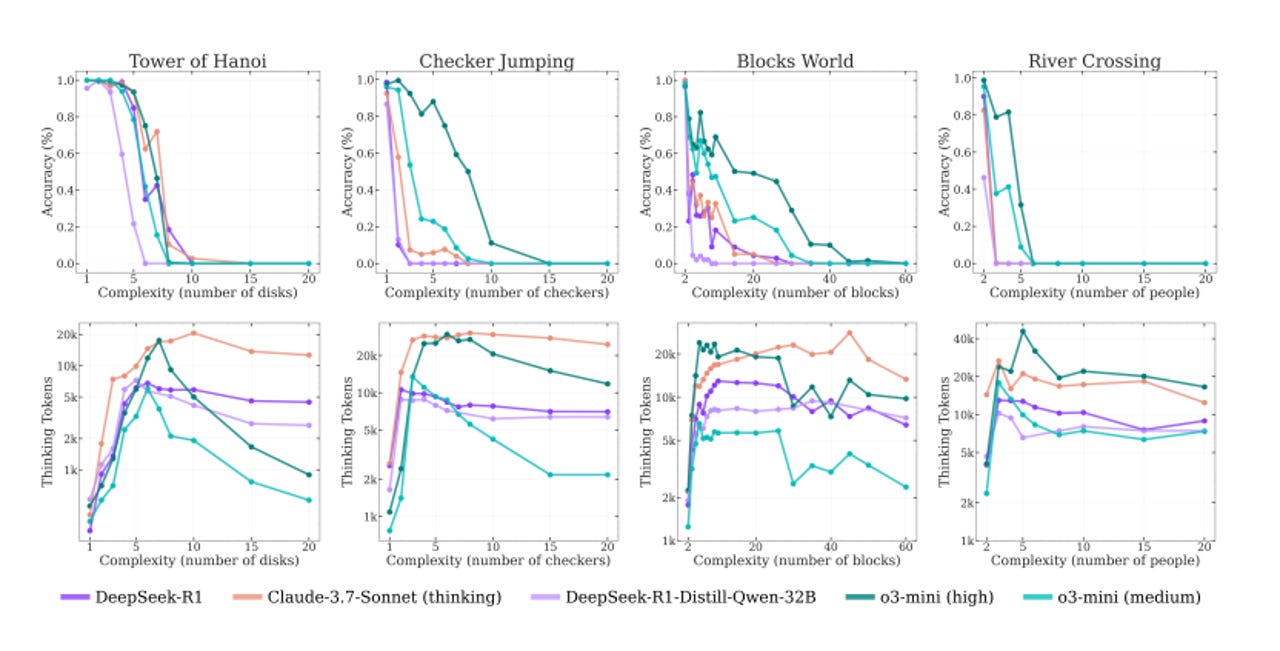
Implications pour l’IA
Les résultats de ce rapport soulèvent des questions sur l’état actuel des modèles de raisonnement. Bien que certains experts considèrent que cela indique un éloignement de l’intelligence générale artificielle (AGI), d’autres critiquent la méthodologie utilisée par Apple. Les critiques portent notamment sur le plafonnement des jetons et le choix des modèles testés.