Le prompt chaining exploite la capacité des grands modèles de langage (LLM) à s’autocorriger naturellement. Cette méthode augmente la précision et la clarté des réponses tout en limitant considérablement le risque d’hallucinations, un phénomène fréquent chez les IA génératives telles que ChatGPT, Claude ou Gemini.

Tous les LLM peuvent générer des informations erronées, mais lorsqu’on leur demande de vérifier la validité d’une source ou d’un fait, ils corrigent souvent leurs erreurs. Le prompt chaining repose précisément sur ce mécanisme d’auto-correction et se présente comme une technique innovante pour améliorer la fiabilité et la clarté des résultats fournis par les modèles de langage.
Qu’est-ce que le prompt chaining ?
Bien que popularisé en 2024, le prompt chaining reste encore peu déployé dans les projets d’intelligence artificielle générative. Son principe est simple : il s’agit de décomposer un prompt complexe en plusieurs prompts plus simples, chacun traitant une tâche spécifique. Les résultats de chaque prompt sont ensuite enchaînés, c’est-à-dire intégrés dans le prompt suivant.
Cette méthode permet de concentrer l’attention du modèle sur une seule étape à la fois, améliorant ainsi la précision globale et réduisant le risque d’inventions factuelles. Selon la complexité de la demande, il est possible de chaîner de un à plusieurs dizaines de prompts.
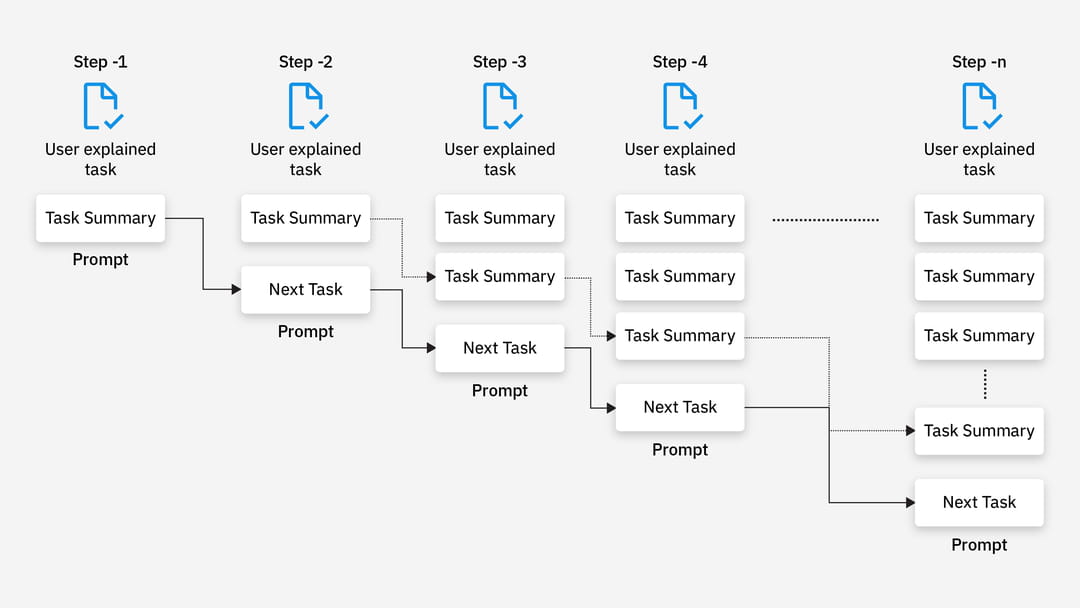
Schéma de fonctionnement d’un prompt chaining. © IBM
Le processus de mise en œuvre est assez simple : il faut identifier les différentes étapes nécessaires à la finalisation de la tâche, puis soumettre chaque sous-prompt l’un après l’autre en intégrant le résultat précédent. Ce déroulement peut être automatisé via des scripts utilisant les appels API des LLM.
Il est conseillé de formuler des instructions claires et concises dans chaque prompt et d’encadrer les sorties précédentes avec des balises XML pour faciliter la compréhension du contexte par l’IA. Bien que cette méthode demande plus de temps pour être élaborée comparée à un prompt unique, elle offre un gain de précision notable.
Exemple concret de prompt chaining
Une application simple du prompt chaining est la réalisation d’une veille quotidienne à l’aide de GPT-4o d’OpenAI :
- Prompt 1 (GPT-4o + recherche web) : « Réaliser une veille d’actualité sur [SUJET] sur les 24 dernières heures. Utilisez uniquement des sources notoirement crédibles. Rédigez une note de veille complète avec un langage clair et précis. »
- Prompt 2 : « Voici ci-dessous une veille d’actualité sur le sujet
$Sortie1 . Comment améliorer la clarté et la pertinence de cette veille ? Suggérez 10 conseils concrets et facilement applicables pour optimiser le texte. Produisez uniquement ces 10 conseils en sortie. » - Prompt 3 : « Voici le texte rédigé d’une veille des 24 dernières heures sur [SUJET], ainsi que les conseils d’amélioration ci-après. Appliquez ces 10 conseils au texte et produisez uniquement la version corrigée. Texte à corriger :
$Sortie1 . Modifications à effectuer :$Sortie2 »
Pourquoi le prompt chaining est-il si efficace ?
Le prompt chaining figure parmi les méthodes les plus puissantes pour obtenir des réponses fiables sur de nombreux sujets. Il s’appuie sur le mécanisme d’attention propre aux LLM, qui leur permet de focaliser leurs ressources sur des éléments clés d’une séquence.
En fragmentant une tâche complexe en plusieurs étapes simples, cette technique diminue la charge cognitive du modèle et encourage un raisonnement structuré, étape par étape.
Les recherches démontrent que les cas impliquant plusieurs étapes, même simples, sont mieux gérés grâce au prompt chaining. Ceci est particulièrement vrai pour :
- La rédaction de textes.
- L’analyse multidimensionnelle de données.
- La création d’agents simples intégrant des outils externes.
Le prompt chaining est aussi recommandé lorsque la traçabilité des réponses est essentielle, car il facilite l’identification précise des étapes posant problème, contrairement à d’autres techniques comme la « chain-of-thought ». En revanche, il est moins utile avec les modèles spécialement entraînés pour raisonner de manière intrinsèque étape par étape, où le bénéfice est moindre.
Approfondir avec la technique du « LLM as a judge »
Cette approche dérivée du prompt chaining vise à augmenter encore la pertinence des résultats. Elle consiste à générer une première réponse avec un modèle A, puis à la vérifier et corriger avec un modèle B différent.
Exemple :
- Prompt avec LLM A : « Génère la biographie de Warren Buffett en 100 mots. »
- Prompt avec LLM B : « La biographie ci-dessous contient-elle des éléments non factuels ? Réponds uniquement par OUI ou NON. Pas d’autre texte.
$Sortie1 »
Si le modèle B répond « NON », la réponse peut être transmise à l’utilisateur. Si la réponse est « OUI », on peut refuser la diffusion ou affiner le prompt pour identifier les erreurs et les corriger.
Pourquoi utiliser un second modèle ? Un même modèle tend à valider ses propres réponses, reproduisant ainsi les mêmes erreurs ou approximations. Chaque modèle dispose de « zones d’ombre » spécifiques, en fonction de son architecture et de ses données d’entraînement. L’emploi d’un second modèle, idéalement plus puissant, limite ce biais d’auto-confirmation. Toutefois, même un modèle évaluateur performant reste susceptible d’halluciner, bien que ce soit plus rare.