La génération augmentée par récupération (RAG) a révolutionné l’intelligence artificielle (IA) en permettant la récupération dynamique de connaissances externes. Cependant, cette méthode présente des limitations telles que la latence et la dépendance aux sources externes. Pour surmonter ces défis, la génération augmentée par cache (CAG) s’est imposée comme une alternative puissante. L’implémentation de la CAG se concentre sur la mise en cache des informations pertinentes, permettant des réponses plus rapides et plus efficaces tout en améliorant la scalabilité, la précision et la fiabilité. Cet article explore comment la CAG répond aux limites de la RAG, examine les stratégies d’implémentation de la CAG et analyse ses applications dans le monde réel.
Qu’est-ce que la génération augmentée par cache (CAG) ?
La génération augmentée par cache (CAG) est une approche qui améliore les modèles de langage en préchargeant des connaissances pertinentes dans leur fenêtre de contexte, éliminant ainsi le besoin de récupération en temps réel. La CAG optimise les tâches nécessitant des connaissances en exploitant des caches clé-valeur (KV) précalculés, ce qui permet des réponses plus rapides et plus efficaces.
Comment fonctionne la CAG ?
Lorsqu’une requête est soumise, la CAG suit une approche structurée pour récupérer et générer des réponses efficacement :
- Préchargement des connaissances : Avant l’inférence, les informations pertinentes sont prétraitées et stockées dans un contexte étendu ou un cache dédié. Cela garantit que les connaissances fréquemment consultées sont disponibles sans nécessiter de récupération en temps réel.
- Mise en cache clé-valeur : Au lieu de récupérer dynamiquement des documents comme le fait la RAG, la CAG utilise des états d’inférence précalculés. Ces états servent de référence, permettant au modèle d’accéder instantanément aux connaissances mises en cache, contournant ainsi la nécessité de recherches externes.
- Inférence optimisée : Lorsque la requête est reçue, le modèle vérifie le cache pour des embeddings de connaissances préexistants. Si une correspondance est trouvée, le modèle utilise directement le contexte stocké pour générer une réponse. Cela réduit considérablement le temps d’inférence tout en assurant la cohérence et la fluidité des résultats générés.
Différences clés avec la RAG
Voici comment l’approche CAG diffère de la RAG :
- Aucune récupération en temps réel : Les connaissances sont préchargées au lieu d’être récupérées dynamiquement.
- Latence réduite : Comme le modèle ne consulte pas de sources externes pendant l’inférence, les réponses sont plus rapides.
- Risque de désuétude : Les connaissances mises en cache peuvent devenir obsolètes si elles ne sont pas rafraîchies périodiquement.
Architecture de la CAG
Pour générer des réponses efficacement sans récupération en temps réel, la CAG s’appuie sur un cadre structuré conçu pour un accès rapide et fiable à l’information. Les systèmes CAG se composent des éléments suivants :
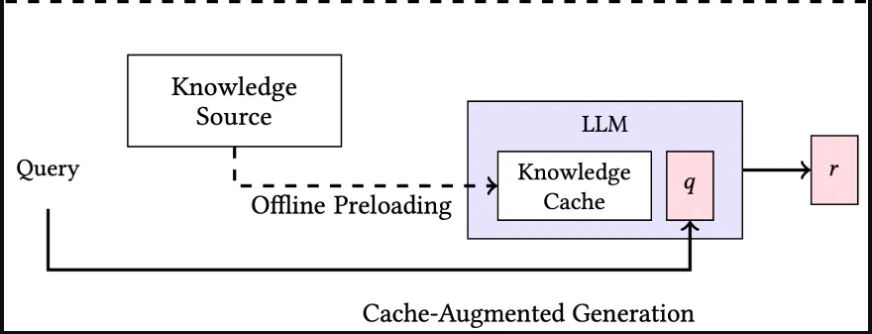
- Source de connaissances : Un dépôt d’informations, tel que des documents ou des données structurées, accessible avant l’inférence pour précharger les connaissances.
- Préchargement hors ligne : Les connaissances sont extraites et stockées dans un cache de connaissances à l’intérieur du modèle de langage large (LLM) avant l’inférence, garantissant un accès rapide sans récupération en direct.
- LLM (Modèle de langage large) : Le modèle central qui génère des réponses en utilisant les connaissances préchargées stockées dans le cache de connaissances.
- Traitement des requêtes : Lorsque la requête est reçue, le modèle récupère les informations pertinentes depuis le cache de connaissances au lieu de faire des demandes externes en temps réel.
- Génération de réponses : Le LLM produit une sortie en utilisant les connaissances mises en cache et le contexte de la requête, permettant des réponses plus rapides et plus efficaces.
Cette architecture est particulièrement adaptée aux cas d’utilisation où les connaissances ne changent pas fréquemment et où des temps de réponse rapides sont nécessaires.
Pourquoi avons-nous besoin de la CAG ?
Les systèmes RAG traditionnels améliorent les modèles de langage en intégrant des sources de connaissances externes en temps réel. Cependant, la RAG pose des défis tels que la latence de récupération, les erreurs potentielles dans la sélection des documents et une complexité accrue du système. La CAG répond à ces problèmes en préchargeant toutes les ressources pertinentes dans le contexte du modèle et en mettant en cache ses paramètres d’exécution. Cette approche élimine la latence de récupération et minimise les erreurs tout en maintenant la pertinence contextuelle.
Applications de la CAG
La CAG est une technique qui améliore les modèles de langage en préchargeant des connaissances pertinentes dans leur contexte, éliminant ainsi le besoin de récupération de données en temps réel. Cette approche offre plusieurs applications pratiques dans divers domaines :
- Service client et support : En préchargeant des informations sur les produits, les FAQ et les guides de dépannage, la CAG permet aux plateformes de service client basées sur l’IA de fournir des réponses instantanées et précises, améliorant ainsi la satisfaction des utilisateurs.
- Outils éducatifs : La CAG peut être utilisée dans des applications éducatives pour fournir des explications immédiates et des ressources sur des sujets spécifiques, facilitant des expériences d’apprentissage efficaces.
- IA conversationnelle : Dans les chatbots et les assistants virtuels, la CAG permet des interactions plus cohérentes et contextuellement conscientes en maintenant l’historique des conversations, conduisant à des dialogues plus naturels.
- Création de contenu : Les rédacteurs et les spécialistes du marketing peuvent tirer parti de la CAG pour générer du contenu qui respecte les directives de la marque et le message en préchargeant des matériaux pertinents, assurant cohérence et efficacité.
- Systèmes d’information en santé : En préchargeant des directives et des protocoles médicaux, la CAG peut aider les professionnels de la santé à accéder rapidement à des informations critiques, soutenant une prise de décision opportune.
En intégrant la CAG dans ces applications, les organisations peuvent obtenir des temps de réponse plus rapides, une précision améliorée et des opérations plus efficaces.
Comparaison CAG vs RAG
En matière d’amélioration des modèles de langage avec des connaissances externes, la CAG et la RAG adoptent des approches distinctes. Voici leurs principales différences :
| Aspect | Génération Augmentée par Cache (CAG) | Génération Augmentée par Récupération (RAG) |
|---|---|---|
| Intégration des connaissances | Précharge les connaissances pertinentes dans le contexte étendu du modèle pendant le prétraitement. | Récupère dynamiquement les informations externes en temps réel en fonction de la requête d’entrée. |
| Architecture système | Architecture simplifiée sans composantes de récupération externe. | Nécessite un système plus complexe avec des mécanismes de récupération. |
| Latence de réponse | Offre des temps de réponse plus rapides grâce à l’absence de processus de récupération en temps réel. | Peut connaître une latence accrue en raison du temps nécessaire à la récupération des données. |
| Cas d’utilisation | Idéal pour des ensembles de données statiques ou rarement changeants. | Adapté aux applications nécessitant des informations à jour. |
| Complexité du système | Simplifiée avec moins de composants. | Impliquant la gestion de systèmes de récupération externes. |
| Performance | Excelle dans des domaines de connaissances stables. | Se développe dans des environnements dynamiques. |
| Fiabilité | Réduit le risque d’erreurs de récupération. | Potentiel d’erreurs de récupération dues aux données externes. |
Quel est le meilleur choix pour votre cas d’utilisation ?
Lors de la décision entre RAG et CAG, il est essentiel de considérer des facteurs tels que la volatilité des données et la taille de la fenêtre de contexte du modèle de langage.
Quand utiliser la RAG :
- Bases de connaissances dynamiques : Idéale pour des applications nécessitant des informations à jour.
- Ensembles de données étendus : Pour des bases de connaissances dépassant la taille de la fenêtre de contexte du modèle.
Quand utiliser la CAG :
- Données statiques ou stables : Excellente pour des ensembles de données peu changeants.
- Fenêtres de contexte étendues : Capable de précharger des quantités substantielles d’informations pertinentes.
Questions fréquentes
Q1. Quelle est la différence entre CAG et RAG ?
A. La CAG précharge des connaissances pertinentes dans le contexte du modèle avant l’inférence, tandis que la RAG récupère les informations en temps réel.
Q2. Quels sont les avantages de la CAG ?
A. La CAG réduit la latence, les coûts API et la complexité du système.
Q3. Quand devrais-je utiliser la CAG plutôt que la RAG ?
A. La CAG est préférable pour des applications où les connaissances sont relativement stables.
Q4. La CAG nécessite-t-elle des mises à jour fréquentes des connaissances mises en cache ?
A. Oui, le cache doit être rafraîchi périodiquement.
Q5. La CAG peut-elle gérer des requêtes à long contexte ?
A. Oui, les avancées dans les LLM permettent à la CAG de stocker des connaissances préchargées plus importantes.
Q6. Comment la CAG améliore-t-elle les temps de réponse ?
A. La CAG évite les appels API en évitant la récupération en direct, accélérant ainsi le traitement des requêtes.
Q7. Quelles sont les applications réelles de la CAG ?
A. Utilisée dans les chatbots, l’automatisation du service client, les systèmes d’information en santé, et d’autres domaines nécessitant des réponses rapides basées sur des connaissances.